Where the Proof Comes From: The Operating Graph Behind Proof-Carrying Operations
By Sid, Founder at Vyuh
In the previous article I argued that a high-stakes, AI-assisted action should carry proof before it crosses the assurance boundary into operation. I left one question unanswered on purpose, and it is the one that actually decides whether any of this survives contact with a real plant: where does that proof come from?
It does not come from a longer prompt, a larger model, more tools, or an agent improvising across operational APIs at the moment of action. The proof comes from structure that already exists before the agent is asked anything. A proof-carrying action is assembled from a governed operating graph that was compiled ahead of time, and it is admitted by a verifier that reads that graph rather than the model's intentions. The graph resolves entities across systems, binds them to concepts and cited rules, exposes a bounded set of capabilities, records where every fact came from, and gives the verifier something deterministic to check. At runtime the model may propose, the operating graph constrains what can be admitted, and the verifier decides what proceeds.
This article is about that substrate. It is deliberately technical, and it is meant to be read as an architecture note rather than a product description. I will define the operating graph, show how it is compiled from brownfield source systems, follow a single proposed action as it is projected out of the graph and checked, and then trace why the same construction keeps appearing far outside process safety. The aim is narrow and, I think, important: to show why proof-carrying operations need a build-time graph, and why the proof cannot be manufactured by an agent at runtime.
1. The admission problem
The first article introduced the assurance boundary, the point at which an AI-assisted recommendation would become an operational action, and wrote admission as a function:
Here C is the capability the agent wants to invoke, E is the evidence packet assembled for the proposed action, G_t is the operating graph at time t, R_t is the applicable rule set, and V is a deterministic verifier. Pass means the action may proceed, fail means it is blocked, and unknown means the system does not yet have enough verified evidence to admit it.
That article spent most of its time on the right-hand side, the three-state result. Here I want to look at the inputs, because the inputs are where almost all of the difficulty lives. A verifier can only be deterministic if what it reads is structured. If it has to parse free text, guess which physical asset a tag refers to, decide which source is authoritative, or infer which standard applies, then it is not deterministic at all; it has simply relocated the guessing one layer down and called it a check. So the hard problem was never only the verifier. It is the build-time system that turns a dozen incompatible source systems into something a verifier can read.
Two objects carry that weight: the operating graph G and the evidence packet E. Even the notation G_t is a little misleading, because it suggests a live mirror of the world that the verifier consults in the present tense. For anything auditable, that is the wrong mental model. The graph should be a sequence of versioned snapshots, and each admission should be evaluated against one specific version of the graph, the rules, and the policy, so the fuller statement is:
The subscripts are not decoration. They are what let a decision be reconstructed months later, after every system it drew from has moved on.
2. Why a runtime agent cannot manufacture proof
It helps to be concrete about what a runtime agent actually has at its disposal, because on paper it looks like plenty. It can retrieve documents, call connectors, read schemas, query a knowledge graph, and invoke tools. All of that is genuinely useful, and none of it, on its own, decides whether a proposed action is admissible. A connector can pull a pressure reading, but it cannot tell you whether that reading is the authoritative source for this decision, whether it is fresh enough to rely on, whether the asset identity has been resolved, or whether the governing rule is blocking. A retrieval system can fetch a standard, but not whether the standard applies to this asset in this operating context. An ontology can define what a reactor is without binding the live state, source authority, freshness, and approvals that an actual decision depends on. A knowledge graph can connect entities and still remain entirely passive: excellent for answering questions, insufficient for governing action.
| Layer | What it does | Why it is not enough |
|---|---|---|
| Search index | retrieves documents | does not define operational meaning |
| Connector | moves data | does not resolve identity, authority, or admissibility |
| Retrieval / RAG | fetches relevant context | does not decide which action is allowed |
| Ontology | defines concepts | does not bind runtime state or permissions |
| Knowledge graph | connects entities and facts | answers questions without governing action |
| Operating graph | constrains action | binds identity, facts, rules, capabilities, freshness, approvals, and audit |
The verbs in that last column are the whole point. A search index retrieves documents, a knowledge graph connects concepts, and an operating graph constrains action. The operating graph is not just a record of what is known; it is a record of what is allowed, under which evidence, for which entity, at which version. That is why "give the agent more tools" is the wrong abstraction. The question is never whether the model can call an API. It is whether this particular call is admissible for this entity, under this evidence, against this policy, with this audit trail, and a model improvising at runtime is the worst possible place to answer it. The proof has to be compiled before the action is ever requested.
3. The operating graph
Before any formalism, it is worth looking at the object itself. The operating graph is not a documentation layer, and it is not a diagram drawn after the system already exists. It is the substrate the verifier will later query. Assets, concepts, source records, rules, capabilities, approvals, and evidence all live in one graph. Systems of record sit around the edge, their partial and often contradictory views get reconciled into canonical entities, those entities are typed to stable concepts, the concepts are governed by cited rules, capabilities declare the evidence they need, and decisions record the exact versions they were made against.
More formally, an operating graph is a versioned directed property graph,
with nodes N, typed directed arcs A, a node-typing function τ and an arc-typing function ρ, a property map π over both, and a version v. A minimal core schema needs about a dozen node types (SourceSystem, SourceRecord, CanonicalEntity, Concept, Rule, Capability, EvidenceClaim, FreshnessPolicy, ApprovalPolicy, Verifier, Decision, and AuditEvent), each carrying a few properties:
| Node | Typical properties |
|---|---|
| SourceSystem | id, owner, authority scope |
| SourceRecord | id, source id, timestamp, source version |
| CanonicalEntity | id, entity type, review state |
| Concept | id, namespace, standard reference |
| Rule | id, version, authority, citation |
| Capability | id, version, target type |
| EvidenceClaim | claim type, value, timestamp, source |
| Decision | result, evaluated-at time, graph version |
and a similarly small set of typed relations connecting them:
| Relation | Meaning |
|---|---|
| SourceRecord resolves_to CanonicalEntity | a source record has been reconciled to a canonical entity |
| CanonicalEntity typed_as Concept | an entity is typed as a stable concept |
| Concept governed_by Rule | a rule applies to a concept |
| Capability requires EvidenceClaim | a capability needs specific evidence before admission |
| EvidenceClaim asserted_by SourceRecord | a claim is supported by a specific source record |
| Decision verified_by Verifier | a decision was admitted or refused by a verifier |
One choice in that schema does more work than the rest: EvidenceClaim is a node, not a log line. Evidence is first-class graph state that exists before a decision is made, not something written down after the fact. The verifier reads evidence that is already in the graph; it never asks the agent to assemble the proof in prose. This is the first real difference from an ordinary knowledge graph. A knowledge graph can tell the agent what is connected. An operating graph tells the system what is allowed.
4. Build-time compilation
The graph is compiled from the source systems in a phase that happens well before any action is requested. The build path is a sequence of inspectable, individually versioned transformations:
Source extraction
Extraction is not just data ingestion. A serious operating graph needs interface extraction: schemas, identifiers, records, timestamps, provenance, available operations, dependency structure, source versions, and authority scopes. The goal is not to flatten source truth away but to preserve it in a form the graph can reason over. A pressure reading from a historian, a functional location from ERP, an equipment tag from engineering, and a permit status from maintenance should stay separately attributable. They may later resolve to the same physical asset, but the graph should never lose the ability to say which source asserted which fact.
Entity reconciliation
Reconciliation resolves multiple source records into one canonical entity. In an industrial setting the same asset routinely shows up as an equipment tag in an engineering model, an asset identifier in an equipment database, a functional location in SAP, a time-series tag in a historian, a live control variable in OPC UA, and a work-order object in maintenance. These are not six assets; they are six partial representations of one real-world object. The method that resolves them is implementation-specific, and it is not what this article is about. The architectural property that matters is simpler and stricter: critical identity resolution happens before action admission, is versioned, and is inspectable. If the system cannot prove that the live tag, the engineering tag, the maintenance object, and the ERP record refer to the same physical asset, the safe admission result is not pass. It is unknown.
Concept typing
Once a canonical entity exists, it is typed to a concept, so that rules bind to stable concepts rather than to brittle source labels.
| Canonical entity | Concept |
|---|---|
| asset:R-501 | reactor |
| asset:E-402 | heat exchanger |
| asset:P-501 | centrifugal pump |
| asset:V-101 | pressure vessel |
A rule that governs reactors binds once to the concept reactor and then applies to every asset that resolves to it, regardless of how each source system happens to spell the equipment. Concept typing creates a stable layer where rules, policies, and capabilities can attach.
Rule binding
A rule is more than retrieved text. For admission it has to become a scoped, versioned predicate over graph state, carrying its own identifier and version, a scope that says which concepts and contexts it applies to, the evidence it requires, a deterministic evaluator for the part of the condition that is actually checkable, a citation to the standard or regulation it comes from, the authority behind it, and a validity window. Binding is then just the statement that a rule attaches to a concept when its scope holds:
A reactor hot-work rule binds to the reactor concept under the relevant operating context; an electrical-clearance rule binds to conductors, substations, or switchgear; a migration-disposition rule binds to a service, code object, or interface. None of these should be retrieved as text at runtime and interpreted by a model. They are bound to graph concepts ahead of the action and then evaluated by a deterministic procedure wherever the condition is checkable. That does not turn every judgment into a deterministic one. Some judgments stay human. But the boundary is explicit: checkable conditions are checked, ambiguous ones escalate, and the model never quietly converts ambiguity into permission.
5. Capabilities as contracts, not tools
The operating graph should never hand an agent raw source-system authority. It exposes bounded capabilities, and a capability is a contract rather than an endpoint. The contract declares what the capability is allowed to do, what target type it applies to, what evidence it requires, what preconditions must hold, what effects it may produce, what effects it explicitly may not produce, how it fails safely, and which verifier admits it. For a hot-work readiness check on a reactor, that contract reads roughly like this:
| Capability field | Example |
|---|---|
| Name | evaluate hot-work readiness |
| Target type | reactor |
| Required evidence | resolved identity, work-order scope, permit status, operating pressure, operating temperature, material inventory, applicable rules, source freshness |
| Preconditions | identity resolved; mandatory sources fresh; no unresolved rule conflict |
| Effects | emit readiness decision; block; escalate |
| Non-effects | does not execute physical work; does not override permit state; does not grant final human authorization |
| Safe failure | missing mandatory evidence or unresolved identity returns unknown; a stale mandatory source fails or returns unknown by policy |
A tool says, here is an API the agent can call. A capability says, here is an action the system may consider, but only under these evidence conditions, with these effects, under this verifier. Agents should not hold root access to the enterprise. They should request bounded capabilities.
6. The evidence packet as a graph projection
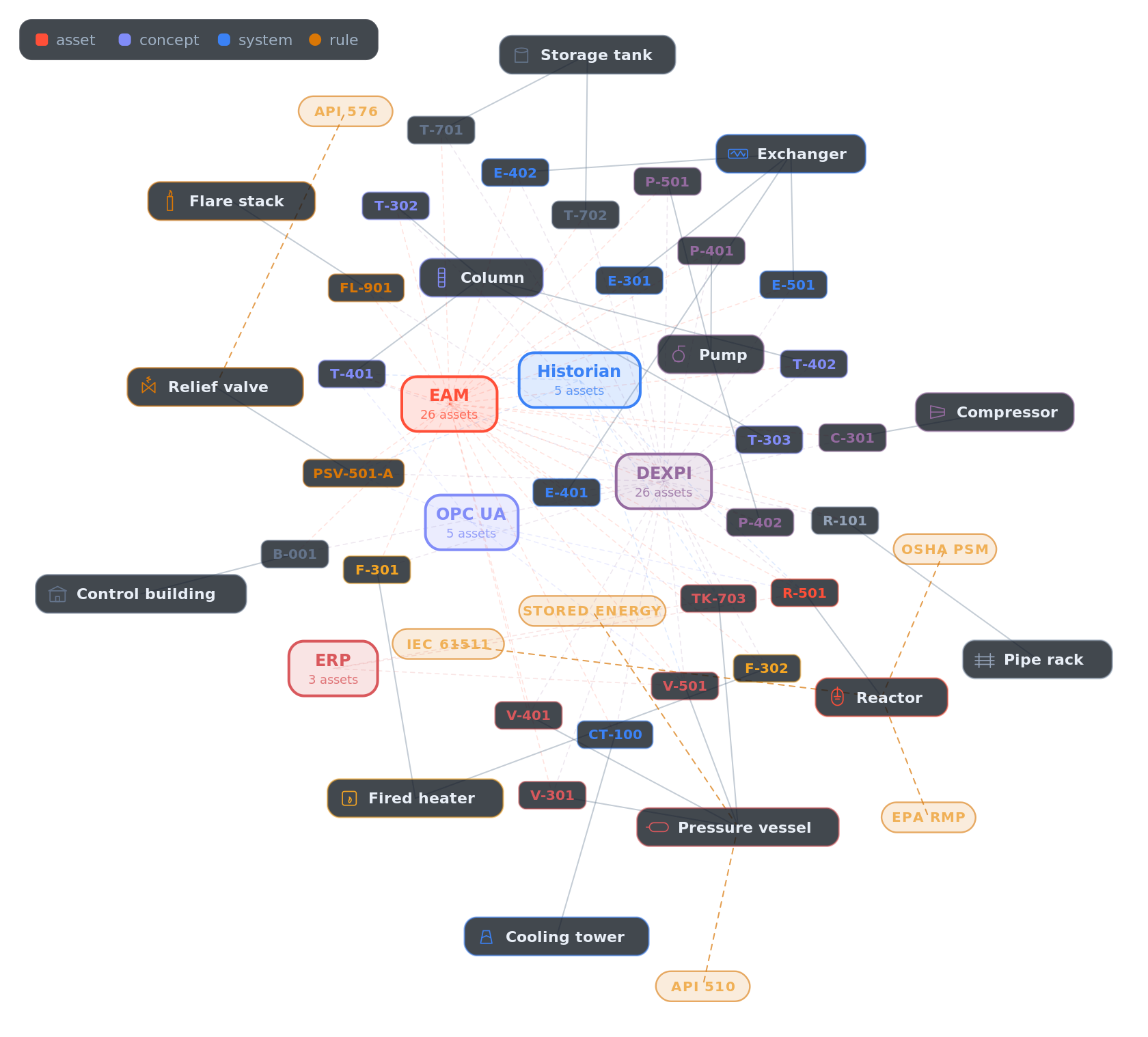
At runtime the verifier does not need the whole graph; it needs the part of the graph that bears on the requested capability. For a request involving R-501, the system projects the neighborhood around the resolved entity: the source systems that assert it, the records that identify it, the concept it is typed as, and the rules that govern the action.
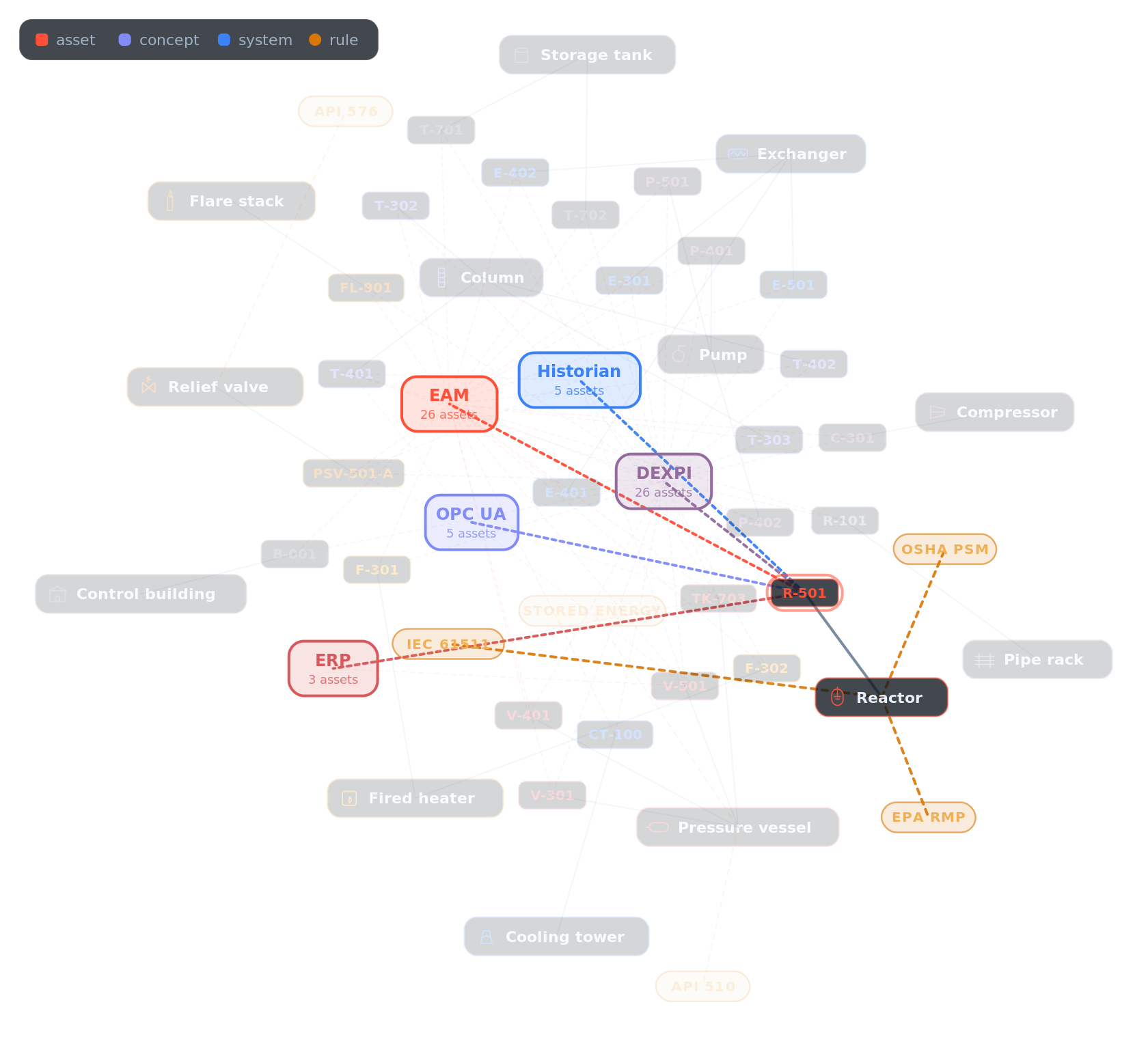
The evidence packet is the result of that projection,
and it carries the request and capability, the canonical target, the source records that resolve to it, the claims the capability requires, the rules bound to the action, the freshness result for each claim, whatever is missing or ambiguous or in conflict, the required approval path and its state, the verifier contract, and the graph, rule, and source versions used, down to a reproducibility hash of the inputs. The central claim is simple to state and easy to get wrong:
The evidence packet is not a free-form explanation. It is a typed projection of the operating graph around one proposed capability invocation.
A model may summarize the packet for a human, explain why the verifier returned fail or unknown, or draft the escalation note. But the packet itself is not generated prose. It is structured state.
7. Deterministic admission
Once the packet exists, admission should be deliberately boring. The verifier checks the packet against fixed versions of the graph, rules, and policy and works through a short list of ordinary questions: is the target identity resolved, are the mandatory claims present and fresh enough, are the relevant rules bound, do any blocking rules fail, does policy allow this capability, are the required approvals present, is the verifier contract itself current, and can the whole decision be reproduced from the recorded versions. The result has three states and no fourth.
| Result | Meaning |
|---|---|
| Pass | the action may proceed |
| Fail | the action is blocked |
| Unknown | the system lacks sufficient verified evidence to admit it |
The safety property that holds the whole design together is just
Unknown is not an inconvenient interface state to be smoothed over. It is the system refusing to convert uncertainty into permission. A human may override or approve through a separate, governed procedure, but the automated path must never silently turn missing evidence, stale evidence, unresolved identity, or ambiguous rule binding into a pass. This is exactly where many agent systems quietly become unsafe: they treat uncertainty as a prompt-engineering problem to be argued away. In high-stakes operations, uncertainty is a control-system output, and it should be allowed to say no.
8. Build time versus runtime
The whole architecture rests on a clean line between build time, where the semantic work happens, and runtime, where bounded execution happens.
| Build time | Runtime |
|---|---|
| source and interface extraction | capability request |
| entity reconciliation | evidence packet assembly |
| concept typing and rule binding | deterministic verification |
| capability and verifier contracts | pass, fail, or unknown |
| reachability analysis | execution, block, or escalation |
| human review of mappings and rules | audit persistence and replay |
| graph versioning | no semantic improvisation |
This boundary does not mean "no language models," which would be the wrong claim. Models can assist build-time extraction, translation, clustering, documentation parsing, and recommendation, and they can help humans build the graph far faster than by hand; they can also help explain a verifier's decision after the fact. The narrower claim is that the runtime admission path should not depend on a model guessing which entity is meant, which source is authoritative, which rule applies, whether the data is fresh enough, whether an action path exists, or whether uncertainty can be ignored. That work belongs in the graph, the policies, the verifier, and the human review loop, not in a runtime prompt.
9. Compile-time reachability
There is a deeper reason to compile the graph before runtime. Resolving identity across systems and finding a valid action path are not really language problems; they are graph problems, and they can be settled before any action is requested. If a capability requires evidence the graph can never supply, the system should know that at build time. If a valid path to a goal exists, it should be discoverable as a build-time artifact, and if it does not, the system should fail fast with a specific reason rather than ask a model to invent one.
The shape of the argument is standard. Suppose there is a canonical field universe U, and a knowledge state is some subset K ⊆ U. Each capability declares the evidence it requires and the evidence it provides,
a capability is callable when at least one of its required clauses is already satisfied by what is known, and calling it only ever grows the known state,
so a planner can forward-chain through the capabilities until it reaches a fixed point, and a goal is reachable exactly when it lies inside that fixed point. The particular planner is not the interesting part; the boundary is. The graph knows which fields are known, each capability declares which fields it requires, the system knows which capabilities can provide the missing ones, unreachable goals fail early, and reachable paths are inspectable. That turns "the agent will figure it out" into something much weaker and much safer: semantic resolution and action planning live in the compiled graph, not in a runtime guess.
10. System invariants
The operating graph earns its keep only if it holds a few invariants, and these are the ones I would not give up.
- No raw authority. An agent requests a typed capability and never receives unbounded source-system access.
- Admission determinism. Given fixed versions of the capability, packet, graph, rules, and policy, the verifier returns the same result every time.
- Unknown is absorbing. The automated path cannot coerce unknown into pass; only a separate, governed human procedure can.
- Evidence is versioned. Every decision records the graph, rule, policy, and verifier versions, the source-record versions, the approval state, and a hash of the packet.
- Evidence precedes action. Evidence is represented before admission, not reconstructed after execution.
- Actions are replayable. Every admitted action can be reconstructed from its request, target, capability, packet, and the versions it used.
- Model output is not admission. A model response is not a pass, and a persuasive explanation is not a verifier result. The verifier admits.
11. Failure modes and safe behavior
A governed operating graph should not be trying to make every request succeed. It should be making the reasons for success, failure, and uncertainty explicit, and in every case the safe direction is toward escalation rather than a silent pass.
| Failure mode | Safe behavior |
|---|---|
| unresolved identity | return unknown; escalate |
| conflicting source records | return unknown; require review |
| stale mandatory source | fail or unknown by policy |
| missing or conflicting rule binding | return unknown; require engineering review |
| capability outside permission | fail |
| graph drift after a decision | expire the prior decision; re-verify |
| unreachable action path | fail fast before runtime |
| source unavailable | degrade the capability; no high-risk pass |
The mindset shift is the point. The purpose of the graph is not to hide uncertainty but to make it structured, and a good verifier is not one that always says yes. It is one that can say exactly why it cannot.
12. Worked example: greenfield siting
The same substrate supports very different autonomy profiles, and the difference is set by the action rather than by the model. In a greenfield layout workflow the proposed action is not to actuate a live asset but to explore candidate layouts and produce a feasible recommendation, and that changes what the agent is allowed to do. The graph here pulls together the process flow diagram for topology and equipment tags, datasheets for footprint and hazard class, ERP and maintenance systems for asset metadata and cost, GIS and geotechnical data for parcels and soil bearing, environmental systems for flood zones and easements, standards for separation and clearance, and physics and cost models for the geometric checks. A candidate vessel resolves through the same path as anything else, from a process-diagram tag to a canonical asset to the concept pressure vessel and the clearance, separation, and cost rules that govern it.
Because the action is low-consequence and reversible, the agent is free to explore the layout space, propose moves, compare site options, and search for cheaper arrangements. The checks underneath it stay deterministic: whether a candidate violates a separation or clearance rule, places critical equipment in a flood zone, creates a spatial conflict, or pushes piping cost past a threshold, and whether the resulting feasibility ledger is reproducible. The ideas can be generative; the checks stay deterministic, and strict conformance attaches at the moment of commitment.
13. Worked example: hot-work readiness
Now take the opposite case, a high-consequence and irreversible decision: a work order proposes hot work on reactor R-501. The reactor is represented in several systems, each with its own identifier, and the graph's first job is to prove they are the same physical object.
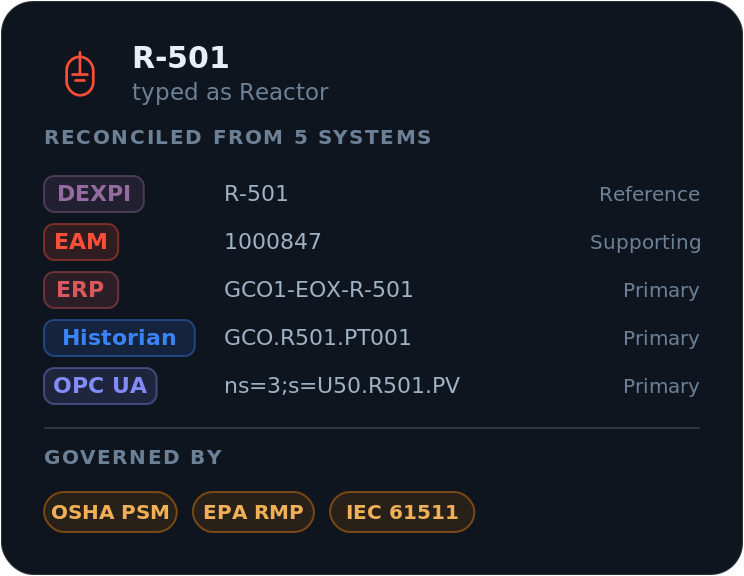
| Source system | Example record |
|---|---|
| DEXPI / engineering | R-501 |
| EAM | 1000847 |
| ERP | GCO1-EOX-R-501 |
| Historian | GCO.R501.PT001 |
| OPC UA | ns=3;s=U50.R501.PV |
The graph resolves all five to a single canonical asset and its rules,
with DEXPI as the engineering reference identity and the other four supplying maintenance, business, process, and live-state records. Source authority is policy-specific: for any given claim the verifier should know which source is authoritative, and it should flag conflicts rather than average them away. For hot-work readiness this resolution is not decorative metadata; it is mandatory evidence. If the system cannot prove that the live tag, the maintenance record, the ERP functional location, and the engineering object all refer to the same reactor, the safe result is unknown, not pass.
The risk here is not in any single fact, it is in the join, which is why the join itself has to be represented, versioned, and verified. It is also why a clever agent sitting on each individual system is not enough. Engineering sees a static reactor, maintenance sees an expired permit, the historian shows a pressure reading, ERP shows inventory, and control shows temperature. Each statement is locally unremarkable, and the hazard only appears when they are joined. A siloed agent can be entirely correct in its own system and still globally unsafe, and the operating graph is the object that makes the join explicit enough to check.
R-501 here is drawn from a demonstration environment. The identifiers are real to that demo, not to a production deployment.
14. What this is not
It is worth being precise about what the operating graph is not, because each of these is a thing it gets mistaken for. It is not RAG: retrieval fetches context but does not define admissible action, and the graph may use retrieved documents at build time without ever letting a model interpret retrieved text as authority at runtime. It is not an ontology alone: an ontology defines concepts and relations but does not by itself bind source records, live state, freshness, permissions, capabilities, verifier contracts, and audit, all of which an ontology can be part of but none of which it is the whole of. It is not iPaaS: connectors move data but do not decide what the data means or whether an action is allowed, and integration is plumbing while admission is governance. It is not master data management: MDM can help answer whether two records are the same entity, but the operating graph also has to answer what action is allowed on that entity, under this evidence. It is not a generic agent framework: those orchestrate tools and usually assume the semantic and action substrate already exists, when the substrate is precisely what is missing. And it is not a dashboard: a dashboard displays state, while the operating graph governs action.
15. Where the pattern generalizes
None of this is specific to process safety. The same construction appears wherever an action depends on facts scattered across systems that were never designed to agree. In plant lifecycle work an asset shows up in engineering models, equipment databases, SAP functional locations, GIS, historians, and maintenance systems, and a lifecycle agent cannot safely reason over it until those identities and rules are reconciled. In grid and utility systems a conductor, span, substation, clearance rule, geospatial location, asset-registry entry, and live measurement can all bear on the same verdict, and a useful grid agent has to return a cited answer rather than a merely fluent one.
In SAP modernization the proof packet is not a hot-work verdict but a migration disposition, retire or replace or rewrite or wrap or review, backed by provenance, schema, code, dependency, usage, and standard evidence. In software more broadly, the same principle becomes a deterministic gate on AI-written code: the agent may propose a change, and the system verifies whether it introduces net-new regressions before it enters the codebase. The model proposes; the verifier admits. SAP, plant lifecycle, grid, and code are not separate stories. They are different proof surfaces for one architecture.
16. Why a shared space rather than pairwise mappings
There is one more reason the work has to happen at build time, and it is a scaling reason. The naive way to connect systems is to map each one directly to each of the others, but the number of pairwise mappings grows quadratically,
which is 45 mappings at ten systems, 1,225 at fifty, and 4,950 at a hundred. That does not survive an enterprise. The workable pattern is to map each system once into a shared semantic space and then compose through that space, which keeps the cost linear in the number of systems and turns cross-system reasoning into traversal over a structured artifact instead of guesswork across arbitrary interfaces. That is the deeper reason build-time compilation matters. Without a compiled substrate, the system ends up asking a model to perform identity resolution, rule applicability, and action planning at the worst possible moment, which is runtime, under consequence, with incomplete context. That is the wrong boundary.
17. Closing
A digital twin can represent the asset. A knowledge graph can connect the concepts. An operating graph constrains the action, and that distinction is the whole difference between an agent that can answer and an agent-assisted system that can be trusted near operations. The next layer of industrial and enterprise AI is not a more capable model placed on top of the twin. It is a versioned graph of entities, rules, capabilities, evidence, policies, and verifier contracts that decides when a recommendation is allowed to become an action.
The graph is compiled before the action is requested. At runtime the agent requests a typed capability, the graph assembles the evidence, and the verifier returns pass, fail, or unknown.
That is where the proof comes from.
References
- Vyuh Labs, "Proof-Carrying Operations: From Digital Twins to Trusted Action," 2026. The first article in this series, which defines the assurance boundary, the three-state verifier, and the evidence packet. /blog/proof-carrying-operations
- George C. Necula, "Proof-Carrying Code," 24th ACM SIGPLAN Symposium on Principles of Programming Languages (POPL '97), 1997. The proof-carrying code lineage that inspired the naming. dl.acm.org
- George C. Necula and Peter Lee, "Safe Kernel Extensions Without Run-Time Checking," 2nd USENIX Symposium on Operating Systems Design and Implementation (OSDI '96), 1996. usenix.org